어텐션(Attention) 메커니즘은 다양한 유형으로 발전해 왔으며, 각 유형은 특정한 문제를 해결하거나 성능을 향상시키기 위해 설계되었습니다. 아래에서는 대표적인 어텐션의 유형 5가지를 소개하고, 각각이 어떤 상황에서 사용되는지를 쉽게 설명해드릴게요.
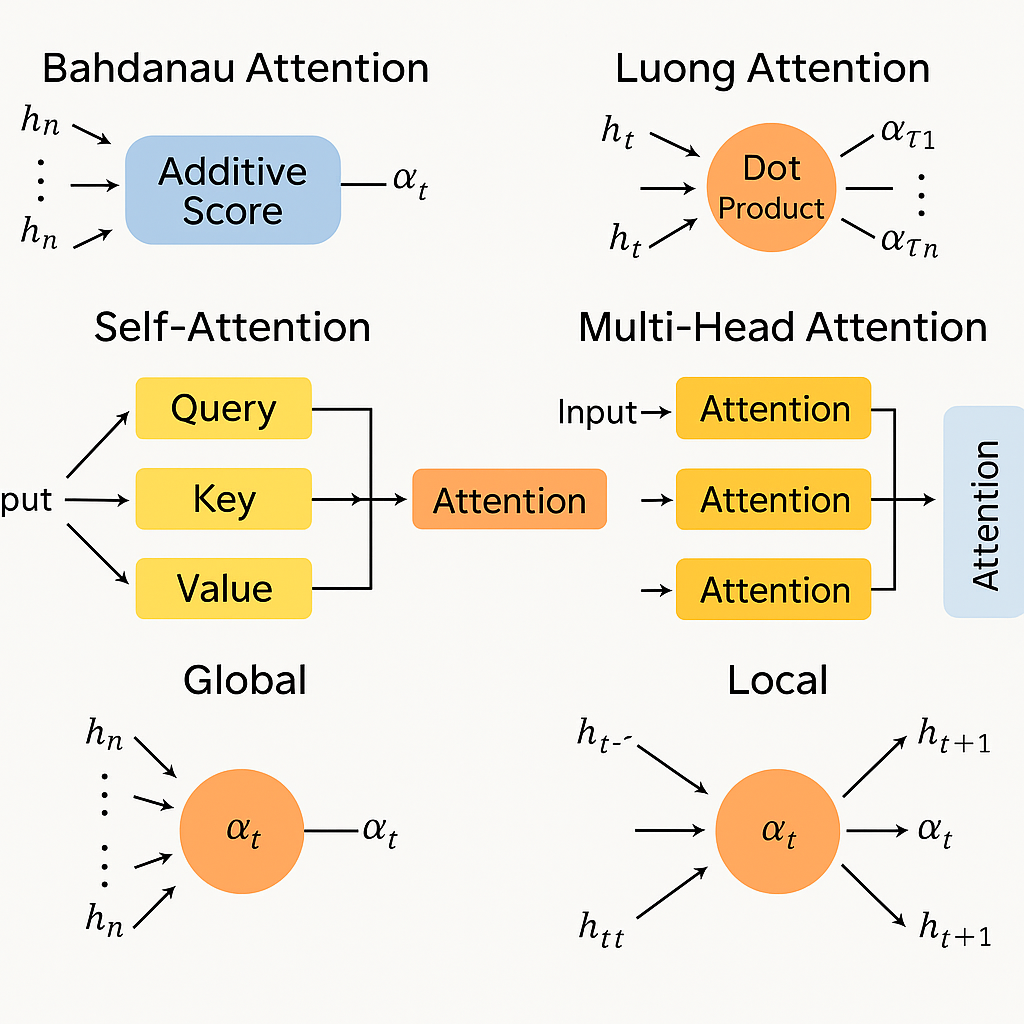
🔍 1. Bahdanau Attention (Additive Attention)
📌 특징
- 초기 어텐션 구조 (2015, Bahdanau et al.)
- 디코더의 현재 상태와 인코더의 각 시점 hidden state를 비교하여 유사도(주의 가중치)를 계산함
- "덧셈 기반(score = tanh(W₁hₑ + W₂h_d))" 방식 사용
🎯 사용처
- RNN 기반 Seq2Seq 구조
- 기계 번역, 문장 요약 등 초창기 NLP 연구에서 널리 사용
🔍 2. Luong Attention (Multiplicative Attention)
📌 특징
- Bahdanau보다 계산량이 적음
- 디코더와 인코더의 hidden state 간 내적(dot product) 또는 행렬곱 방식으로 유사도를 계산
🎯 주요 차이점
- Bahdanau: 더 복잡하고 성능 좋음
- Luong: 더 단순하고 빠름
둘 다 RNN 계열 Seq2Seq 모델에서 사용됩니다.
🔍 3. Self-Attention (자기 주의)
📌 특징
- 한 문장 내에서 각 단어가 다른 단어들과의 관계를 모두 살펴봄
- 문장 내에서 중요한 단어끼리 서로 주의를 주고받음
- Transformer 모델의 핵심 구성 요소
🎯 사용처
- BERT, GPT, T5, ViT 등 거의 모든 최신 딥러닝 모델
- 문맥 고려, 병렬 처리, 긴 거리 관계 학습
예: "The animal didn't cross the street because it was too tired." → "it"이 가리키는 것이 "animal"이라는 걸 알아내기 위해 앞뒤 문맥 전체를 고려해야 함
🔍 4. Multi-Head Attention
📌 특징
- Self-Attention을 여러 개 병렬로 수행함
- 각 헤드는 다른 관점에서 주의를 계산하므로, 더 풍부한 표현 학습 가능
🎯 핵심 구조
- 각 Head는 서로 다른 가중치를 학습하며 다양한 문맥 정보를 추출
- 최종적으로 여러 Head의 결과를 Concat → Linear → 출력
Transformer의 Encoder/Decoder 층에 핵심적으로 사용됨
🔍 5. Global vs. Local Attention
구분Global AttentionLocal Attention
| 구분 | Global Attention | Local Attention |
| 범위 | 전체 입력 시퀀스를 모두 고려 | 특정 위치 중심의 작은 창(window)만 참고 |
| 장점 | 정보 손실 적음 | 계산 효율 높음 |
| 사용 예시 | 번역, 질문응답, 문장 생성 | 실시간 처리, 장문 분할 처리 등 |
📌 요약 비교 표
어텐션 종류방식주요 특징사용 모델 예시
| 어텐션 종류 | 방식 | 주요 특징 | 사용 모델 예시 |
| Bahdanau (Additive) | Feedforward + tanh | 정밀하지만 느림 | RNN 기반 Seq2Seq |
| Luong (Multiplicative) | Dot product | 계산 효율적 | RNN 기반 Seq2Seq |
| Self-Attention | Query-Key-Value | 문장 내 관계 파악, 병렬 처리 가능 | Transformer, BERT |
| Multi-Head Attention | 여러 Self-Attention | 다양한 관점에서 정보 추출 | Transformer, GPT |
| Local Attention | 슬라이딩 윈도우 방식 | 계산량 적고 빠름 | 일부 음성/스트림 처리 |
'인공지능' 카테고리의 다른 글
| 🔄 인코더(Encoder)와 디코더(Decoder)란? (0) | 2025.05.26 |
|---|---|
| 🚀 트랜스포머란? (0) | 2025.05.26 |
| seq2seq와 어텐션 메커니즘을 결합한 모델이 트랜스포머? (0) | 2025.05.26 |
| 어텐션 메커니즘과 Seq2Seq 모델과의 관계 (0) | 2025.05.26 |
| RNN (Recurrent Neural Network)의 한 종류 LSTM (0) | 2025.05.26 |